import os
import glob
import requests
import json
import re
import time
# --- 1. 設定 (Qwen2.5を使用) ---
OLLAMA_URL = "http://localhost:11434/api/generate"
MODEL_NAME = "qwen2.5:latest" # すでにリストにあるモデルを使用
INPUT_DIR = '.'
OUTPUT_DIR = '../modern_math'
TARGET_PATTERN = 'sec*.html'
def ask_local_ai_to_fix(html_text):
prompt = (
r"あなたは数学専門のWeb編集者です。HTML内の数学表現(fontタグ、iタグ等)をLaTeX形式 \( ... \) に修正してください。"
"\n【厳守】日本語文章とHTML構造は一切変えず、修正後のHTMLコードのみを返してください。"
)
payload = {
"model": MODEL_NAME,
"prompt": f"{prompt}\n\n{html_text}",
"stream": False,
"options": {
"temperature": 0, # 正確性を最大化
"num_ctx": 16384 # 大きなファイル対策
}
}
try:
response = requests.post(OLLAMA_URL, json=payload, timeout=None)
if response.status_code == 200:
result = response.json()['response']
# 余計な装飾の除去
clean_html = result.replace('```html', '').replace('```', '').strip()
return clean_html
return f"ERROR: HTTP {response.status_code}"
except Exception as e:
return f"ERROR: {str(e)}"
def main():
if not os.path.exists(OUTPUT_DIR): os.makedirs(OUTPUT_DIR)
processed_files = set(os.listdir(OUTPUT_DIR))
all_files = sorted(glob.glob(os.path.join(INPUT_DIR, TARGET_PATTERN)))
files_to_process = [f for f in all_files if os.path.basename(f) not in processed_files]
print(f"--- 修正開始 (残り {len(files_to_process)} 個) ---")
for i, fpath in enumerate(files_to_process):
fname = os.path.basename(fpath)
print(f"[{i+1}/{len(files_to_process)}] 処理中: {fname}...", end="", flush=True)
# 読み込み
with open(fpath, 'r', encoding='utf-8', errors='replace') as f:
file_content = f.read() # ここで内容を定義
# AIに渡す (変数名を file_content に統一)
result = ask_local_ai_to_fix(file_content)
if result.startswith("ERROR"):
print(" 失敗")
else:
with open(os.path.join(OUTPUT_DIR, fname), 'w', encoding='utf-8') as f:
f.write(result)
print(" 成功")
# --- CPU冷却のための休憩 (3秒) ---
# 68°Cまで上がった温度を逃がすためのインターバルです
time.sleep(3)
if __name__ == "__main__":
main()
|
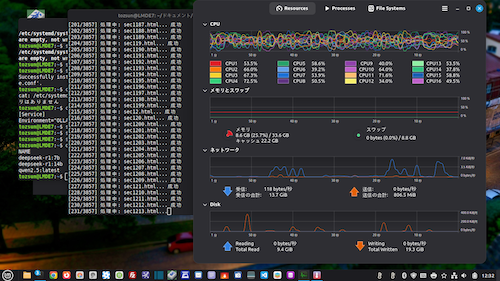
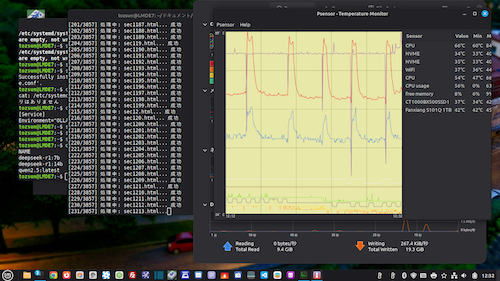 ホームページのタグの関係で、プログラム中の「<」「>」は全角表示しています。
ホームページのタグの関係で、プログラム中の「<」「>」は全角表示しています。